A Pre-implemented Module Flow¶
This section describes a pre-implemented module flow that can operate in two ways:
Target high performance implementations by reusing high quality, customized solutions.
A rapid prototyping demonstration vehicle that hints at a future of fast compile times.
Background and Flow Comparison¶
Both flows (high performance and rapid prototyping) start with the RapidWright provided Tcl command, rapid_compile_ipi. This command can be loaded by running source ${::env(RAPIDWRIGHT_PATH)}/tcl/rapidwright.tcl in the Vivado Tcl interpreter. Optionally, you can also configure Vivado to source the script each time it starts by modifying the Vivado_init.tcl (see the section ‘Loading and Running Tcl Scripts’ in UG894: Vivado Design Suite User Guide - Using Tcl Scripting).
Note
If you are using a standalone jar, you can extract the rapidwright.tcl (and other device/data) by running java -jar <standalone.jar> --unpack_data and setting the environment variable RAPIDWRIGHT_PATH to the standalone jar location.
This command runs on an open IP Integrator design by synthesizing, placing and routing all IP blocks out-of-context (OOC). Each block is provided a pblock (area constraint before placement to improves its re-usability). The implemented result for each IP is stored in the Vivado IP cache. RapidWright then uses the cache for each subsequent run (and only pre-implements one of each kind of IP—so if your design has multiple instances, only one run per type). After all IPs have been implemented OOC, it invokes the BlockStitcher in RapidWright to stitch all of the pre-implemented blocks together, places the blocks and routes them into a final implementation (note: currently RapidWright router is disabled). This command, can function in two modes as described previously. Here is a quick comparison of the high performance vs. rapid prototyping mode for pre-implemented blocks:
High Performance Flow |
Rapid Prototyping Flow |
|
|---|---|---|
PBlock Selection |
Application Architect (Manual) |
PBlock Generator |
Block Placement |
Application Architect (Manual) |
Block Placer |
Global Routing |
Vivado |
RapidWright Router OR Vivado |
The high performance flow (as described in more detail in the High Performance Flow section below) requires input from the application architect of the design. This does involve extra effort, but leads to potentially the highest implementation results. The Rapid Prototyping Flow is optimized more for fast compile times by automating the tasks of pblock selection for each block/IP involved and also placement of the blocks.
Module Cache¶
In order to better facilitate fast loading performance of modules, RapidWright has a fast and efficient file format for storing modules in a directory called a cache. The facilities for reading and writing these module storage files are found in the BlockCreator class found in the ipi package. As each IP to be implemented in a design might have different physical contexts or placement pblocks, multiple implementations of the same Module are stored in a ModuleImpls object which is simply an extended ArrayList<Module>. This allows all the implementations to reside in the same object and file and to reference each unique implementation with an index. Each RapidWright module entry has three relevant files:
Input: A metadata text file generated from Vivado to communicate information about the IP, its ports, clocks, constraints and approximate delays on inputs and outputs. This file is read into RapidWright during the module file creation process.
Output: To store the physical implementation data of each module implementation, a ‘.dat’ file is created from
BlockCreator.Output: The logical netlist is shared among all implementations and is stored in a compressed EDIF file format with a ‘.kryo’ extension.
The RapidWright module cache builds on top of the IP cache in Vivado. By default RapidWright puts the cache in the $HOME/blockCache directory. This can be changed by setting the environment variable IP_CACHE_PATH before running the flow.
The IP cache generated by Vivado is supplemented by RapidWright by providing placed and routed DCPs and module files in each hash-named directory for each non-trivial IP. By default, the flow only creates a single implementation for each IP. Later, we describe how a user can create an implementation guide file (‘.igf’) directing the flow to create multiple unique implementations of the same module/IP.
Block Stitcher¶
The block stitcher (found in the class BlockStitcher of the ipi package) is the heart of the pre-implemented design flow. It manages the flow progress and ensures that all blocks have been cached and retrieved appropriately. It also reads in the IP Integrator netlist file (EDIF) that describes the block connectivity and stitches together the block implementations in the physical netlist. It also reads and parses the implementation guide file (if provided) and creates the block implementations accordingly.
High Performance Flow¶
One of the key attributes of RapidWright is the ability to capture optimized placement and routing solutions for a module and reuse them in multiple contexts or locations on a device. Vivado often provides good results for small implementation problems (smaller than 10k LUTs within a clock region). However, when those same modules are combined into a large system, total compile time increases and the probability of timing closure is reduced. This phenomenon limits achievable performance and timing closure predictability of larger designs.
RapidWright endows users with a new design vocabulary by caching, reusing and relocating pre-implemented blocks. We believe this to be an enabling concept and offer a three-step high performance design strategy:
Restructure the Design: Expose all modular pieces and replication in an IP Integrator design.
Packing & Placement Planning: Craft custom pblocks and placement patterns to match architecture layout and resources.
Stitch, Place & Route Implementation: Run the automated flow to create a final implementation.
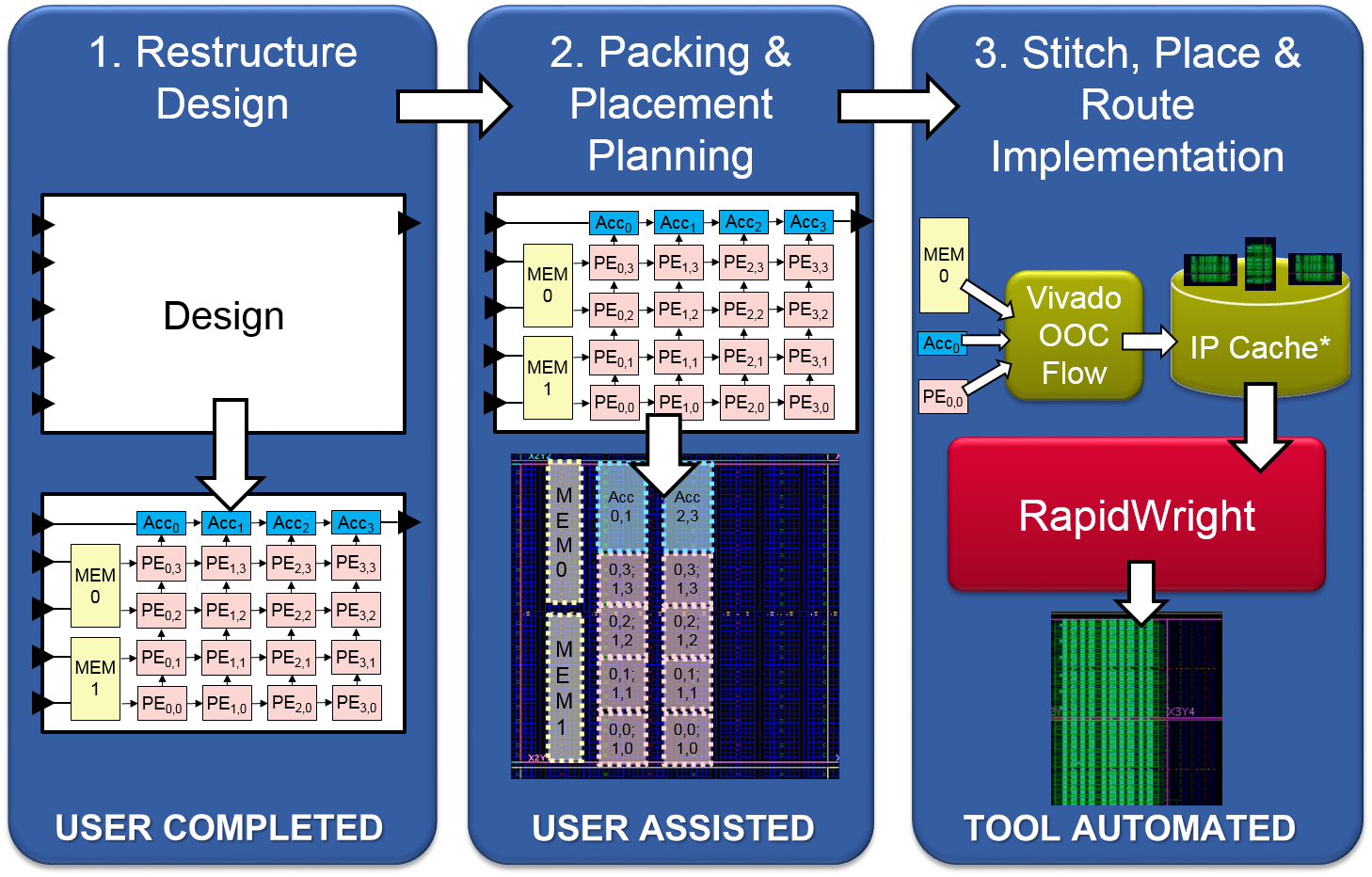
High level visual of the three step process for the high performance module-based design strategy¶
The first step requires the design architect to restructure the proposed design such that it can take full advantage of the benefits provided by pre-implemented modules. We define restructuring as a design refactoring that reflects three favorable design characteristics: (1) modularity, (2) module replication and (3) latency tolerance. Modularity uncovers design structure so it can be strategically mapped to architectural patterns. When modules are replicated, reuse of those high quality solutions and architectural patterns can be exploited to increase the benefits. Finally, if the modules within a design tolerate additional latency, inserting pipeline elements between them improves both timing performance and relocatability.
After the design architect has successfully restructured and modularized a design, step two is followed. Here, the design architect creates an implementation guide file that captures how best to map the modules of a design to the architecture of the target device. Specifically, pblocks are chosen for those pre-implemented modules of interest and physical locations are chosen for each instance. This step provides the design architect an opportunity to navigate FPGA fabric discontinuities. These discontinuities include boundaries such as IO columns, processor subsystems, and most significantly, SLR crossings. Such architectural obstacles cause design disruptions when targeting high performance. However, by leveraging a pre-implemented methodology provided in RapidWright, custom-created implementation solutions can be identified and planned out to manage the fabric discontinuities by custom module placement. Ultimately, this process is iterative and can inform useful RTL/design changes by focusing design structure to better match architectural resources.
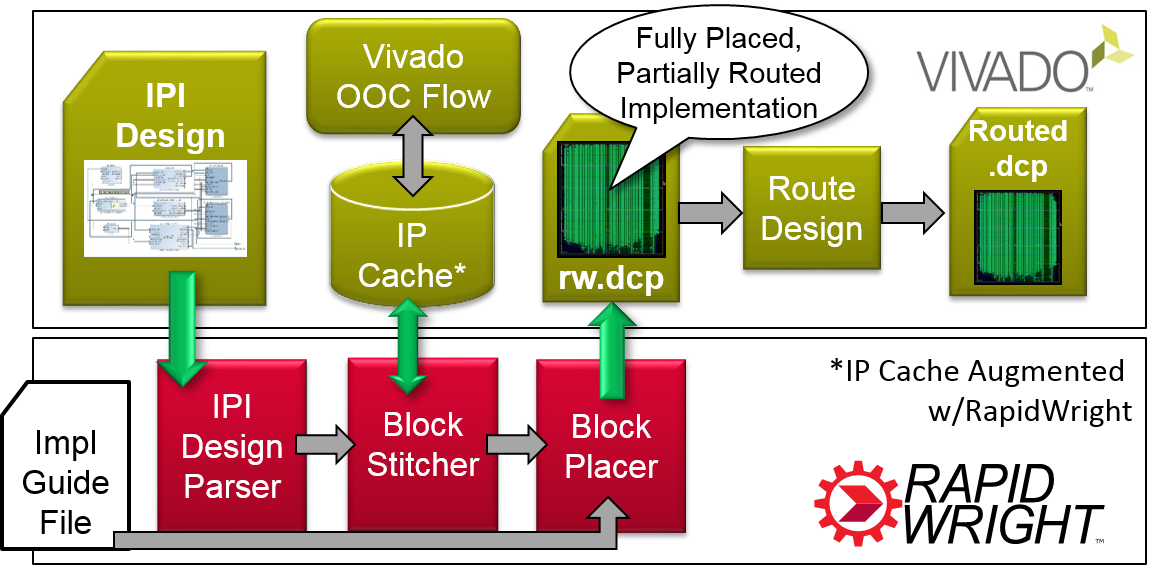
High level view of the pre-implemented flow process and interactions between Vivado and RapidWright¶
Step three of the design strategy is an automated flow provided with RapidWright (depicted in the diagram above). We leverage a design input method in Vivado called IP Integrator (IPI). IPI offers an interactive block-based approach for system design by providing an IP library, IP creation flow and IP caching. RapidWright takes advantage of IPI by using leaf IP blocks as de-facto pre-implemented blocks and also by leveraging the IP caching mechanism. The RapidWright pre-implemented flow extends the caching mechanism to go beyond synthesis, by performing OOC placement and routing on the block within a constrained area. The flow begins by invoking Vivado’s typical IPI synthesis and creating pre-implemented blocks for each module if not already found in the cache. RapidWright has an IPI Design Parser (EDIF-based) that creates a black-box netlist where each instance of a module is empty, ready to receive the pre-implemented module guts. The block stitcher reads the IP cache and populates the IPI design netlist. After stitching, the blocks are placed either by loading the implementation guide file or invoking a simulated annealing module placer to place the blocks onto the fabric automatically. Once all the blocks are placed, RapidWright creates a DCP file that is read into Vivado which completes the final routes.
Implementation Guide File¶
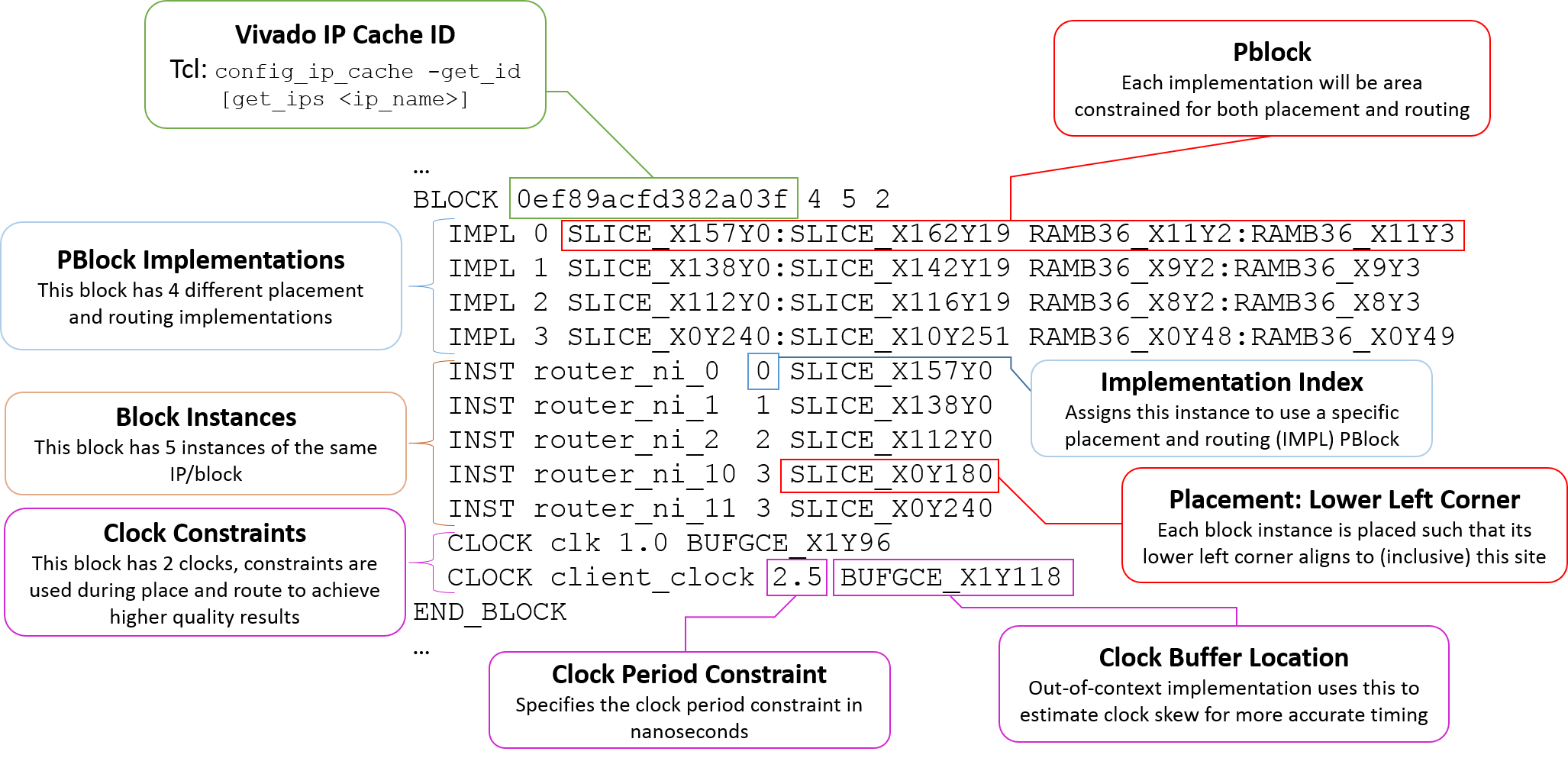
An implementation guide file (extension *.igf) allows the application architect to communicate all of the specific implementation customization aspects of the packing and placement phase. The file has the following syntax structure (note the use of … which indicates a potential repetition of the previous construct):
PART <part_name>
BLOCK <ip_cache_id> <# of implementations> <# of instances in the design> <# of clocks used in this block>
IMPL <implementation index> [# of sub implementation entries] <Pblock range>
[SUB_IMPL <sub implementation index> '<Tcl command returning a subset of cells in the module>' <pblock range>]
...
...
INST <instance name> <implementation index to apply> <lower left corner site to place implementation on fabric>
...
CLOCK <clock name> <clock period constraint (ns)> <BUFGCE site (to use for skew estimation)>
...
END_BLOCK
...
END_BLOCKS
A parser and export for the IGF format can be found in com.xilinx.rapidwright.design.blocks.ImplGuide.readImplGuide(String fileName) and com.xilinx.rapidwright.design.blocks.ImplGuide.writeImplGuide(String fileName).
BLOCK (IP Cache Entry)¶
The block construct describes all of the potential implementations for a particular block/IP. For each uniquely configured IP (entry in the IP cache), there exists a block. Multiple instances of the same block/IP can exist and this construct allows the application architect to map instances by name to a specific implementation.
IMPL (Implementation)¶
Each block has one or more IMPLs. Each implementation carries a pblock and potentially some SUB_IMPL which allows for sub pblocks to be applied to portions of the logic inside the block. Each IMPL is indexed so that it can be referenced and applied to specific instances of the block. The application architect takes special care in selecting implementations and their pblocks to maximize there potential performance, architectural footprint and placement packing efficiency.
SUB_IMPL (Sub Implementation)¶
This is an optional construct that allows for more fine-grained pblocks being applied to a partial subset of the block/IP in an implementation. One field requires a Tcl command that returns a subset of cells that should be included in the sub implementation and associated pblock. Multiple sub implementation entries can exist for each implementation. As an example, if a particular IP is tall and narrow and there are specfic cells that need to be placed at the top and/or bottom, the SUB_IMPL contruct can be used to pblock the top and bottom specific cells in sub pblock of the overall implementation.
INST (Instance)¶
In each design, there will be one or more instances of a block/IP. Each instance has a unique name and must be assigned to an implementation. Each instance also requires a placement which is provided by denoting a specific site onto which the lower left corner of the pblock of the respective implementation could be placed.
CLOCK (Clock Input)¶
The clock construct describes a clock input to the block or IP and allows it to apply a clock period constraint in nanoseconds. It also requires the BUFGCE site from which the clock will be driven so that during placement and routing, the clock skew can be estimated.
Rapid Prototyping Flow¶
When an implementation guide file is not provided when calling the rapid_compile_ipi command, the flow defaults into a rapid prototyping flow that targets faster compilation. As no user input is provided to guide pblock selection or block placement, RapidWright provides automated facilities that accomplish these tasks automatically, albeit with lower average performance than the application architect.
Automatic PBlock Generator¶
The automatic pblock generator is found in the design.blocks package in the class called PBlockGenerator. It takes as input two files to calculate an appropriate pblock for a given circuit. First it uses a utilization report file (produced by Vivado’s report_utilization command) to identify the types of resources needed and their quantity. Second, it reads a shapes report file that describes all of the shapes in the design to ensure that the pblock size can easily accommodate all shapes. Shapes are an internal Vivado construct to help small groups of cells be placed together (such as carry chains). In the pre-implemented flow, the PBlockGenerator is always invoked for each IP that is created, specific Tcl commands are found in the tclScripts/rapidwright.tcl file in the compile_block_dcp proc.
One of the techniques used by the PBlockGenerator is to identify the most common tile column patterns (see TileColumnPattern class in the device.helper package) found in a particular device and place the pblock onto the most common match for a given resource footprint to maximize the place-ability of the block.
Expectations for performance should be muted as the prioritization for the pblock generator is to produce a pblock that won’t cause place and route to fail and lacks knowledge of the particular context of the design where the block may be destined. For this purpose, it is highly recommended that any performance critical block or design use the implementation guide file as a way to better optimize the pblock for a particular application.
Additional research and development work has been made by providing an improved horizontal block density algorithm described in Improved Horizontal Block Density.
Block Placer¶
The Block Placer (found in the class BlockPlacer2 of the package placer.blockplacer), uses a simple simulated annealing schedule to place the blocks on to the fabric. The cost function is a function of total wire length between blocks. Again, like the pblock generator, the block placer attempts to produce valid results, with less emphasis on performance.
Router¶
The router is a very simple maze router with very limited routing congestion avoidance. Its clock router is still a work in progress and is currently disabled. It is currently tuned to work with UltraScale and UltraScale+ architectures. The Router class is found in the router package.